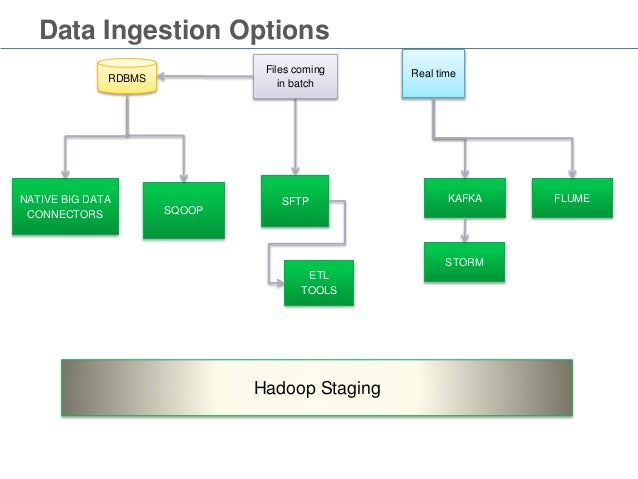
Data Ingestion phase for migrating enterprise data into Hadoop Data Lake. Traditional ELT (Extraction from sources then loading into cluster and eventually transformation to process ) can be used like dumping data files through FTP using crone job but have limitations.
Hadoop Data ingestion is the beginning of your data pipeline in a data lake. Now, let's have a look at how we import different objects Streaming Ingestion. Data appearing on various IOT devices or log files can be ingested into Hadoop using open source Ni-Fi.
Now, I want to insert data into this table. Can I do something like this? insert into foo (id, name) VALUES (12,"xyz) First, copy data into HDFS. Then create external table over your CSV like this. CREATE EXTERNAL TABLE TableName (id int, name string)
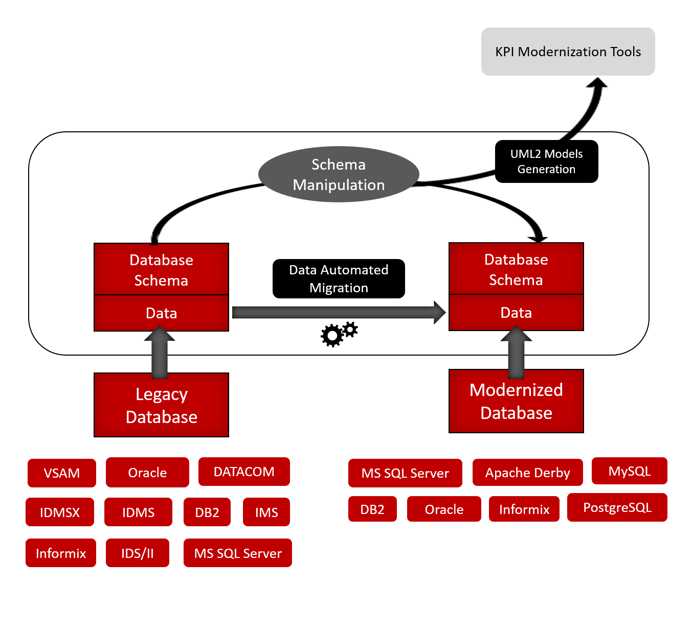
Consolidating all enterprise data into a single Hadoop data lake solves a number of problems, and offers some very attractive benefits But once the decision has been made to migrate to a Hadoop data lake, how is that task best accomplished? RCG|enable™ Data.
ingestion hadoop rdbms etl sqoop flume kafka
export REPORTNAME="Employee_Info_Report Tables Data Ingestion from Oracle to Hadoop Job" export OUTPUTFILE=/ export REPORTRECEIPEINT=javachain@

data lake hadoop lakes experience plan
Hortonworks data scientists focus on data ingestion, discussing various tools and techniques to import datasets from external sources into Hadoop.
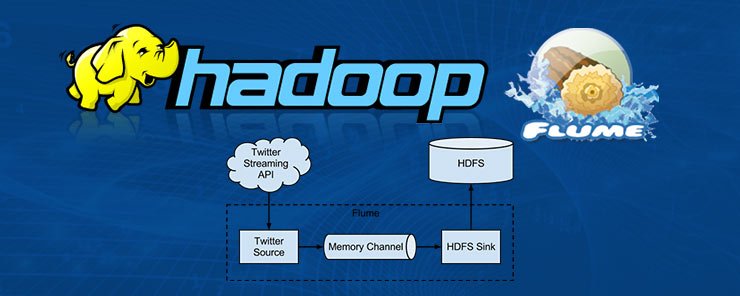
The data is ingested in the HDFS component of Hadoop. views ·. View upvotes. Flume is a Java-based ingestion platform that is used when input data comes in faster than it can be processed. Flume is typically used to ingest streaming data into HDFS or Kafka topics, and it can also serve
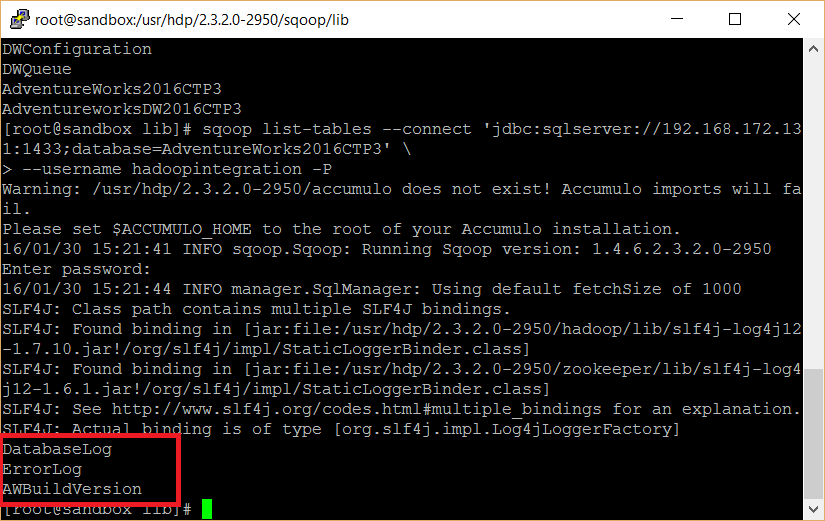
export HADOOP_MAPRED_HOME=/usr/local/hadoop Check if sqoop has been correctly installed by running sqoop version at the It has shown how to get data from a table and use the where clause to filter data. It has also shown how to import an entire
This pages provides some thinking around how to ingest data from NAS to HDFS. Once data is copied to your cluster edge server, you can use hadoop fs command to copy from local to HDFS as the first This API call returns a location of datanode server address where the data will be written into.
Running MapReduce jobs on ingested data is traditionally batch-oriented: the data must be first transferred to a local file system accessible to the Code was borrowed from the Atlantbh website and integrated into the canonical WordCount Hadoop program. The key ingredient here is how

hadoop hdfs yield efficiency accelerating workflows greater application conclusion
flume hadoop apache stream learn using data

ingestion hadoop etl rdbms sqoop
Creating data ingestion pipelines that can gracefully handle data drift without having to write custom code is very easy and straightforward in Data Collector. Modernizing Hadoop Ingest: Beyond Flume and Sqoop. Look at easy-to-use StreamSets Data Collector for creating modern data flow
Generally people use Sqoop to ingest data from any RDBMS system to Hadoop, but Sqoop comes with very small set of features and for most of the big organizations, it is not a good choice. As Sqoop is CLI based, not secure and do not have much feature to track which data is going where.
Informatica PowerCenter provides high performance connectivity to access and ingest most any type of structured or unstructured data into Hadoop, without hand-coding or staging.
Hadoop is one of the best solutions for solving our Big Data problems. In Hadoop we distribute our data among the clusters, these clusters help by computing the data in parallel. It is the simplest way of putting or ingesting data into Hadoop.
Lesson 5: In Experimentation and Running Algorithms in Production you learn how to test the accuracy of machine learning models and how to integrate them into a running big data architecture. Lesson 6: Basic Visualizations teaches you about D3, a
How will you gather this data for your analysis? A. Ingest the server web logs into HDFS using Flume. B. Write a MapReduce job, with the web servers for Hadoop MapReduce for Parsing Weblogs Here are the steps for parsing a log file using Hadoop MapReduce: Load log files into the HDFS
The full Hadoop stack provides an almost unlimited number of ways to get data into and out of HDFS. Even more when you go into the 1. You can directly copy data to Hadoop Distributed File System using 'copyFromLocal' or 'Put' regardless of data structure if
data warehouse modernization deliver process services workflow service
sqoop hadoop
I want to insert my data into hive like. INSERT INTO tablename VALUES (value1,) I have read that you can load the data from a file to hive table or you can import data from one table to hive table but is there any way to append the data as in SQL?
Ingesting Data Using Sqoop and Oracle GoldenGate. Transforming Data Using Hive, Spark, or Pig. Loading Data to Oracle DB using Oracle Loader for In this section, you will learn how to ingest data from external sources into Hadoop, using Sqoop for bulk load and Oracle GoldenGate for
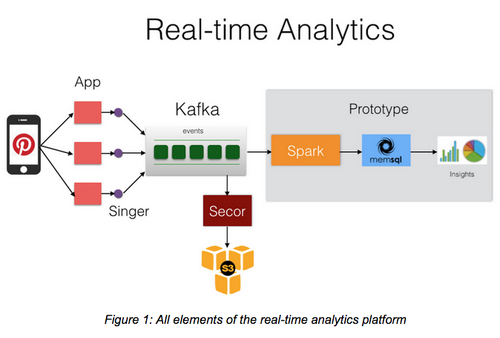
spark apache analytics enterprise using insidebigdata engineering credit frankel image1
Insert statement is used to load DATA into a table from query. Example for the state of Oregon, where we presume the data is already in another table called as staged- employees. Let us use different names for the country and state fields in
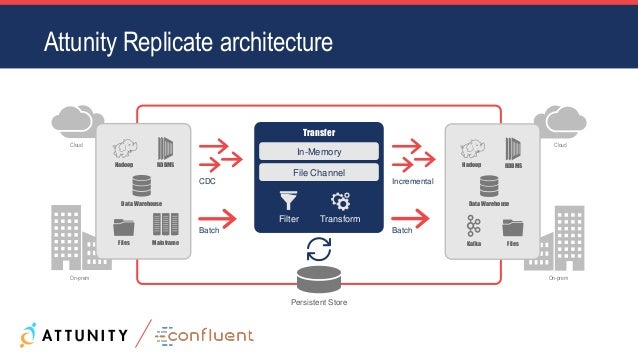
kafka apache ingest attunity cdc
Export data: Move old data to Hadoop while keeping it query-able via an external table. INSERT INTO [dbo].[HistoricalSales] With this small tutorial I demonstrated how to use SQL Server 2016 and Hadoop to create a cost effective and functional archiving solution.
• Easy data ingestion: Copying data to and from the MapR cluster is as simple as copying data to a standard file system using Direct Access NFS™. Applications can therefore ingest data into the Hadoop cluster in real time without any staging areas or separate clusters just to ingest data.
You can use various methods to ingest data into Big SQL, which include adding files directly to HDFS, using Big SQL EXTERNAL HADOOP tables, using Big The following article presents an overview of various ingestion techniques and explains some best practices for considering number of files,
Big data expert Patrick Lie introduces Hadoop and walks through setting up a basic database cluster and running a MapReduce job. Hadoop is a platform for storing and processing large amounts of data in a distributed and Hadoop can be broken up into two main systems: storage and computation.
How to find the best Cloudera data ingestion tools. Talend Data Fabric handles all aspects of data ingestion, including transforming and loading data into source systems. Try Talend Data Fabric today to securely ingest data you can trust into your Hadoop ecosystem.
$ $HADOOP_HOME/bin/hadoop fs -ls
Renders options for ingesting data into Hadoop. Contribute to mhausenblas/hadoop-data-ingestion development by creating an account on GitHub.
This post described how to ingest email into Hadoop from an journal stream in real time. Conveniently, it is common practice to convert other types of electronic communication into email format for archiving purposes. Such data can then be ingested precisely as described above.
Turn your data into revenue, from initial planning, to ongoing management, to advanced data science application. Ingest a single table from Microsoft SQL Server Data into Hadoop. This blog describes the best-practice approach in regards to the data ingestion from SQL Server into Hadoop.
When you ingest data into Druid, Druid reads the data from your source system and stores it in data files called segments. One exception is Hadoop-based ingestion, which uses a Hadoop MapReduce job on YARN MiddleManager or Indexer processes to start and monitor Hadoop jobs.
