Declarative ETL pipelines: Instead of low-level hand-coding of ETL logic, data engineers can leverage SQL or Python to build declarative pipelines - easily defining 'what' to do, not 'how' to do it. With DLT, they specify how to transform and apply business logic, while DLT automatically manages all
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift About Note: Since this project was built for learning purposes and as an example, it functions only for a An AWS s3 bucket is used as a Data Lake in which json files are stored. The data is extracted from a json and parsed (cleaned).
What is an ETL pipeline? ETL stands for Extract-Transform-Load. Essentially, it is a 3-part batch process for migrating In this article, we briefly went over the theory and principles of well-designed ETL pipelines, and then we explored a realistic example of how to build one such pipeline in Python.
ETL Pipeline Architecture. Extract. Transform. Load. How to Build an ETL Pipeline? ETL Pipeline is a set of processes that involve extracting data from sources like transactional databases, APIs, marketing tools, or other business systems, transforming the data, and loading it into
Extract, transform, load (ETL) is the main process through which enterprises gather information from data sources and replicate it to destinations like data warehouses for use with business intelligence (BI) tools. There are benefits to using existing ETL tools over trying to build a data pipeline from scratch.
eckerson altexsoft analyst
Discussing how to build an ETL pipeline for database migration using SQL Server Integration Services (SSIS) in Visual Studio 2019. Extract data from table Customer in database AdventureWorksLT2016 on DB server#1. Manipulate and uppercase
A Data Pipeline into ElasticSearch. ETL Pipeline Instructions: Step-By-Step. Get Running Minutes. Achieve Cloud Elasticity with Iron. Our worker in this example will be very simple as a reference point. With the flexible capabilities of IronWorker, you are free to build out any transformations you'd

pipeline kafka etl dzone
Methods of building ETL pipelines can be broadly classified into two categories: batch processing and real-time processing. ETL pipelines are one of the most widely utilized process workflows in businesses today, enabling them to benefit from deeper analytics and complete business information.

gofundme alooma etl data load saasworthy murder

jenkins selenium pipeline automated testing build
Create an ADF Pipeline that loads Calendar events from Offfice365 to a Blob container. Run a Databricks Notebook with the activity in the ADF pipeline, transform extracted Calendar event and merge to a Delta lake table. To build the pipeline, there are a few prerequisites that need to be met
Writing your ETL pipeline in native Spark may not scale very well for organizations not familiar with maintaining code, especially when business requirements Why adopt SQL to build Spark workloads? When writing Spark applications, developers often opt for an imperative or procedural approach
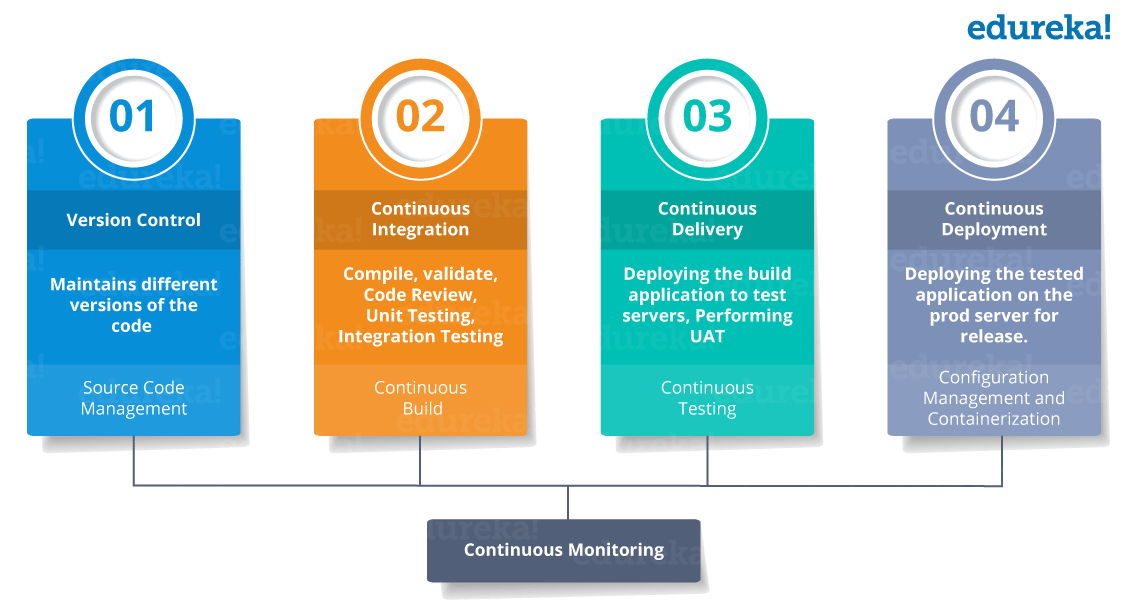
ci pipeline cd devops software stages development continuous integration cicd process deployment lifecycle delivery stands setup scratch learn edureka
Extract, transform, load (ETL) is one of the most critical parts of data integration. The process can be quite difficult if you are writing your code for the data ETL pipeline. Most data professionals acknowledge that the manual ETL process is very cumbersome and requires advanced expertise
This post focuses on one particular ETL pipeline developed by our team. The task was to parse 200-something gigabytes of compressed JSON logs, filter relevant entries, do some data massaging, and finally dump the results into an SQL database.

data azure factory step service pipeline configuration build simple technet wiki components
Tutorial: Discover how to build a pipeline with Kafka leveraging DataDirect PostgreSQL JDBC driver to move the data from PostgreSQL to HDFS. One of the major benefits for DataDirect customers is that you can now easily build an ETL pipeline using Kafka leveraging your DataDirect JDBC drivers.
What Is ETL. ETL stands for Extract, Transform, Load. Extraction is the process by which data We are currently building an ETL Data processing pipeline for a project that involves raw data being How can I get this instance running locally? Git Clone the project you can find it on the Akquinet
ETL pipelines are available to combat this by automating data collection and transformation so that analysts can use them for business insights. There are a lot of different tools and frameworks that are used to build ETL pipelines. In this post, I will focus on how one can tediously build an ETL
etl fme
Learn how to transform and load (ETL) a data pipeline from scratch using R and SQLite to gather tweets in real-time and store them for future analyses. Therefore, in this tutorial, we will explore what it entails to build a simple ETL pipeline to stream real-time Tweets directly into a SQLite
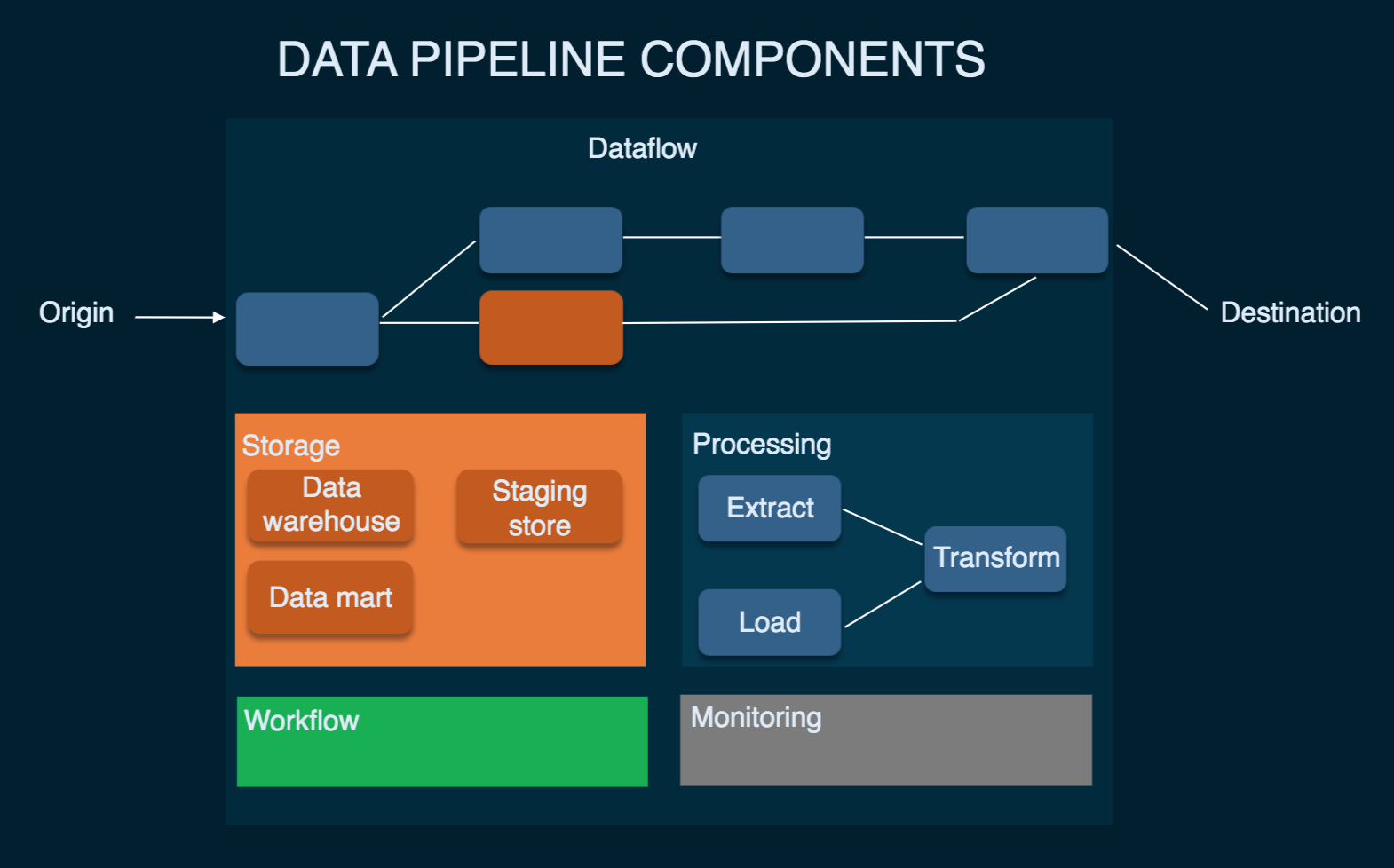
An ETL pipeline is a software architecture design that describes a specific type of data pipeline. The ETL pipeline flows data from source systems to target systems. The extract phase extracts or collects data from raw data sources, such as APIs, sensors, marketing tools, and other sources of data.
Cloud Data Fusion, powered by open-source CDAP, lets you build and manage ETL data pipelines. See how to automate deployments with Terraform. Cloud Data Fusion is a fully managed, cloud-native data integration service that helps users efficiently build and manage ETL data pipelines.
In my last post, I discussed how we could set up a script to connect to the Twitter API and stream data directly into a database. Today, I am going to show you This concludes our two-part series on making a ETL pipeline using SQL and Python. Although our analysis has some advantages and is
Build ETL Pipeline with Real-time Stream Processing. Many sources like social media, e-commerce websites, etc. produce real-time data that requires In this blog post, we guided you through the structured approach on what is ETL and how you can build an ETL pipeline. We have also listed
In this blog post we saw how an ETL pipeline for Jira can be built and used to transform data from a rather complex and heterogenous format to a clear structure that can now be used for many other applications. In the next post we will investigate how project related KPIs can be calculated based
In this article, we review how to use Airflow ETL operators to transfer data from Postgres to BigQuery with the ETL and ELT paradigms. At first, you may be tempted to build an ETL pipeline where you extract your data from Postgres to a file storage, transform the data locally with the
Create ETL pipelines for batch and streaming data with Azure Databricks to simplify data lake ingestion at any scale. The solution in this article meets that need with an architecture that implements extract, transform, and load (ETL) from your data sources to a data lake.
How Helps With Building an ETL Pipeline in Python. An ETL pipeline is the sequence of processes that move data from a source (or several sources) into a database, such as a data warehouse.
Data pipelines built from this hodgepodge of tools are brittle and difficult to manage. Kafka Connect is designed to make it easier to build large scale, real-time data pipelines by standardizing how you In this blog, we built an ETL pipeline with Kafka Connect combining the JDBC and HDFS connectors.
This video demonstrates how to build your first Spark ETL pipeline with StreamSets' Transformer Engine. Design your pipeline in a simple, visual canvas
Learn how to build an ETL pipeline with some help from Apache Airflow and ECS Fargate. Usually, one ETL tool is used to cover all three of these steps, , extracting, cleaning, and loading data. ETLs have become an essential aspect that ensures the usability of data for analytics, reporting, or
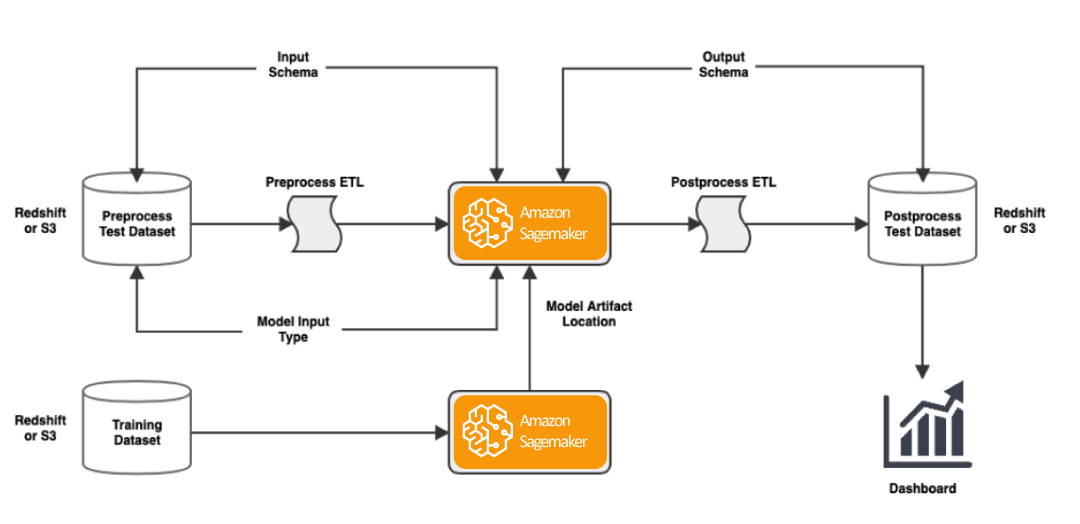
sagemaker
Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow. It is then transformed/processed with Spark (PySpark) and loaded/stored in either a Mongodb database or in an Amazon Redshift Data Warehouse.
ETL is the process of extracting data from a variety of sources, formats and converting it to a single format before putting it into database. Previous Post Complete guide on How to use Autoencoders in Python. Next Post How to Build a Book Recommendation System.
peptide bond formation creation clues artificial purpose provides polypeptide disulfide diagram reaction amide shown formed
ETL (Extract, Transform, Load) is an automated process which takes raw data, extracts the information required for analysis, transforms it into a format that can Let's start by looking at how to do this the traditional way: batch processing. 1. Building an ETL Pipeline with Batch Processing.
