30, 2015 · Apache Spark is an open source big data processing framework built around speed, ease of use, and sophisticated analytics. In this article, Srini Penchikala talks about how Apache Spark framework ...
In this post, I am going to discuss Apache Spark and how you can create simple but robust ETL pipelines in it. You will learn how Spark provides APIs to transform different data format into Data…

tensorflow datasets tensorboard logical
The focus here is deploying Spark applications by using the AWS big data infrastructure. From my experience with the AWS stack and Spark development, I will discuss some high If you have a Spark application that runs on EMR daily, Data Pipleline enables you to execute it in the serverless manner.
Deeplearning4j on Spark: How To Build Data Pipelines. As with training on a single machine, the final step of a data pipeline should be to produce a DataSet (single features arrays, single label array) or MultiDataSet (one or more feature arrays, one or more label arrays).
As the release of Spark finally came, the machine learning library of Spark has been changed from the mllib to ml. One of the biggest change in the It only meant to guide you on how to build Spark ml pipeline in Scala. The choices of data munging decisions as well as the models are not optimal
Spark Structured Streaming Use Case Example Code. Below is the data processing pipeline for this use case of sentiment analysis of Amazon product review data to detect positive and negative reviews. On-Premise Adventures: How to build an Apache Spark lab on Kubernetes. Jun 15, 2021.
With Spark , the Spark on Kubernetes project is officially production-ready and Generally Available. More data architecture and patterns are available for Why do we need to build a codeless and declarative data pipeline? Data platforms often repeatedly perform extract, transform, and load (ETL)...
25, 2019 · Firstly, the grandparent, the most senior level of our ADF pipelines. In our grandparent pipeline my approach would be to build and consider two main operations: Attaching Data Factory Triggers to start our solution execution. Either scheduled or event based. From Logic Apps or called by PowerShell etc. The grandparent starts the processing.
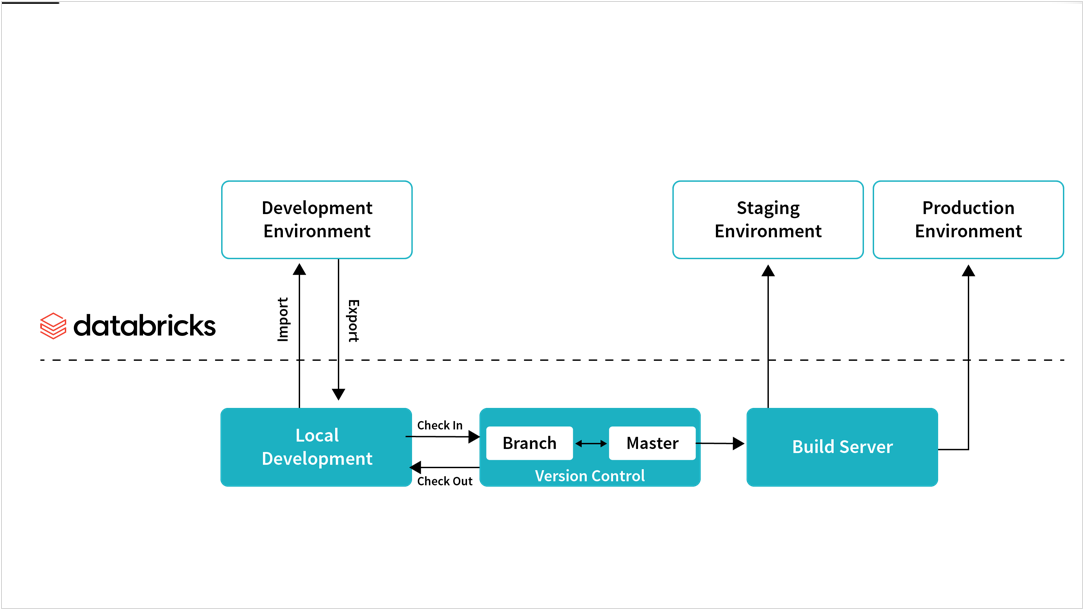
databricks apache
Sparks, through MLlib, provide a set of feature's transformers meant to address most common transformations needed then we'll read dataset and will start to manipulate data in order to prepare for the pipeline. Afterwards, we'll filter out all missing values and we'll be ready to build the pipeline.
Building the data pipeline for A/B testing with the lambda architecture using Spark helped us to have quick view of the data/metrics that get generated with a streaming job, and a reliable view from a scheduled batch process. Using Spark/Spark Streaming helped us to write the business
Spark program creates a logical plan called Directed Acyclic Graph (DAG) which is converted to physical execution plan by the driver when driver program runs. Continuous Delivery. We outline the common integration points for a data pipeline in the CD cycle and how you can
about Azure Data Factory data pipeline pricing—and find answers to frequently asked data pipeline questions. ... Build your business case for the cloud with key financial and technical guidance from Azure. ... Spark, R Server, HBase and Storm clusters.
Scalable, reliable, secure data architecture followed by top notch Big data leaders. Detailed explanation of W�s in Big Data and data pipeline building and automation of the In this Big Data project, a senior Big Data Architect will demonstrate how to implement a Big Data pipeline on AWS at scale.
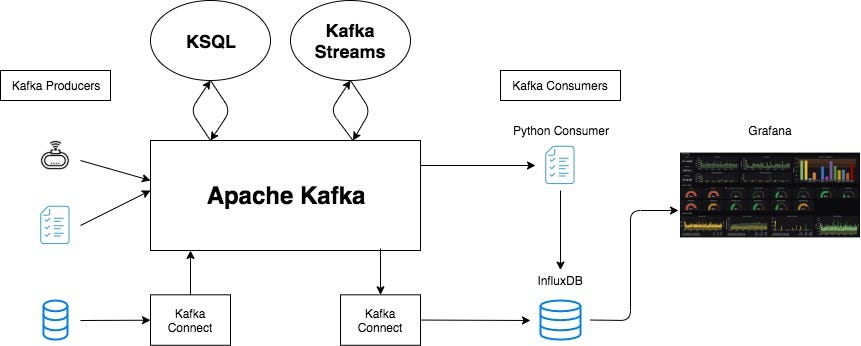
kafka grafana influxdb ksql
With support for building Machine Learning data pipelines, Apache Spark framework is a great choice for building a unified use case that It's used for implementing data pipelines. In this article, we learned about how to use Spark ML package API and how to use it in a text classification use case.

streamanalytix etl apache
Additionally, a data pipeline is not just one or multiple spark application, its also workflow manager that handles scheduling, failures, retries and This is why I am hoping to build a series of posts explaining how I am currently building data pipelines, the series aims to construct a data pipeline from
A senior developer gives a quick tutorial on how to create a basic data pipeline using the Apache Spark framework with Spark, Hive, and some In this post, we will look at how to build data pipeline to load input files (XML) from a local file system into HDFS, process it using Spark, and load the
Spark Structured Streaming is a new engine introduced with Apache Spark 2 used for processing streaming data. It is built on top of the existing Spark Structured Streaming models streaming data as an infinite table. Its API allows the execution of long-running SQL queries on a stream
Spark Streaming is part of the Apache Spark platform that enables scalable, high throughput, fault tolerant processing of data streams. To sum up, in this tutorial, we learned how to create a simple data pipeline using Kafka, Spark Streaming and Cassandra.
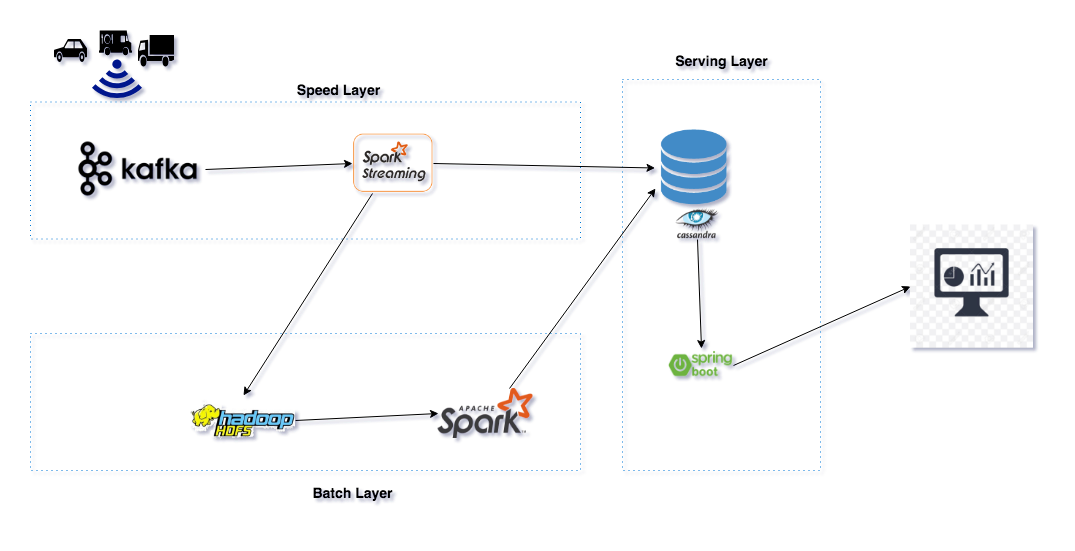
lambda dzone
Basics of Spark ML pipeline API. DataFrames. DataFrame is a Spark SQL datatype which is used as Datasets in ML pipline. A Dataframe allows storing structured data into named columns. A Dataframe can be created from structured data files, Hive tables, external databases, or existing RDDs.
The ability to know how to build an end-to-end machine learning pipeline is a prized asset. As a data scientist (aspiring or established), you should know Perform Basic Operations on a Spark Dataframe. An essential (and first) step in any data science project is to understand the data before building
airflow-spark-data-pipeline's Introduction. In this work, user want to have understand behaviour of user went they integrate with application. Building stream application to ingress and egress data of both user and application data. Technical consideration.
times it is worth it to save a model or a pipeline to disk for later use. In Spark , a model import/export functionality was added to the Pipeline API. As of Spark , the DataFrame-based API in and has complete coverage. ML persistence works across Scala, Java and Python.
21, 2022 · Data factory will display the pipeline editor where you can find: All activities that can be used within the pipeline. The pipeline editor canvas, where activities will appear when added to the pipeline. The pipeline configurations pane, including parameters, variables, general settings, and output. The pipeline properties pane, where the ...
Spark's ML Pipelines provide a way to easily combine multiple transformations and algorithms This step just builds the steps that the data will go through. This is the somewhat equivalent of doing this in R Another nice feature for ML Pipelines in sparklyr, is the print-out. It makes it really easy to
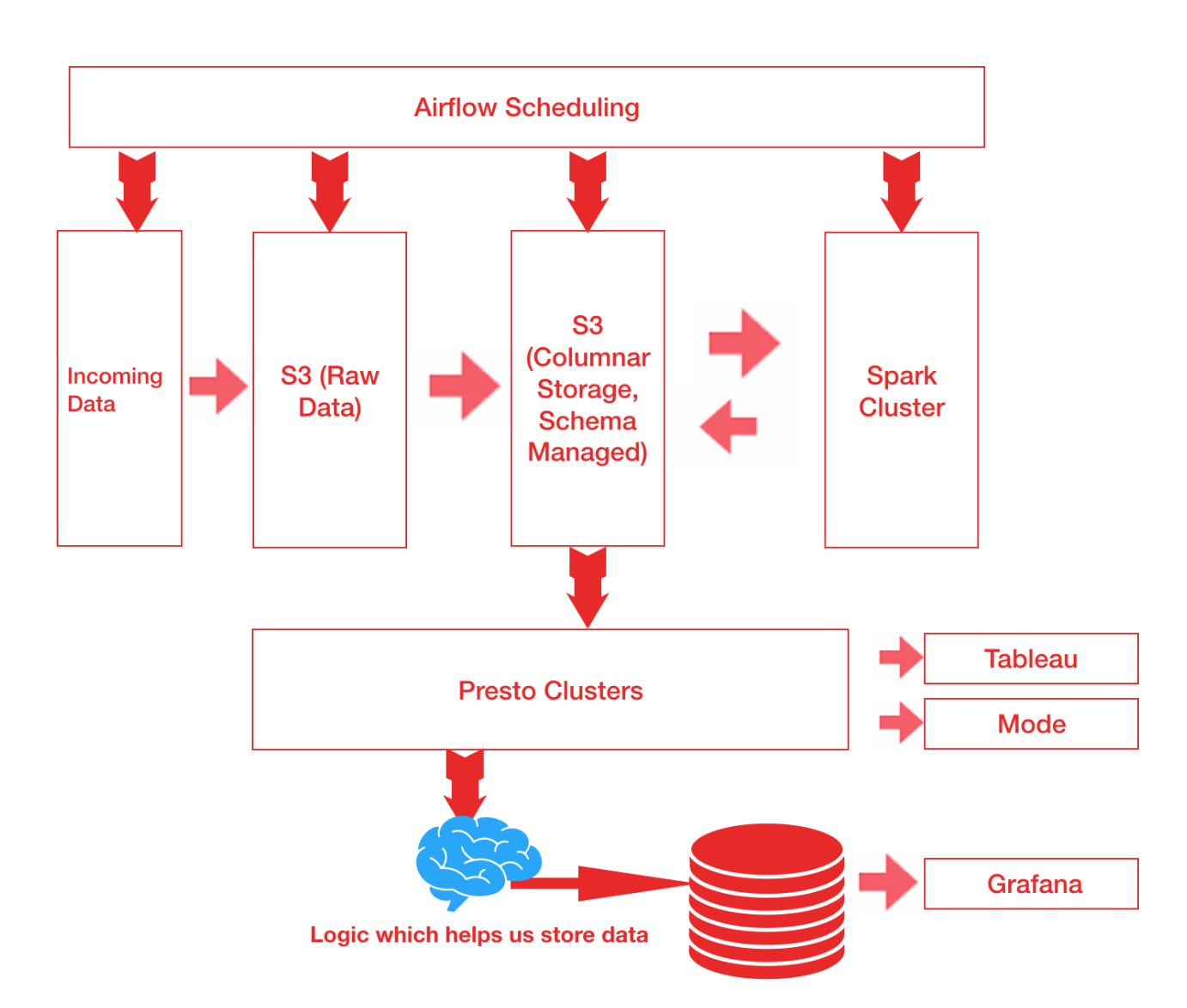
pipelines manish cost
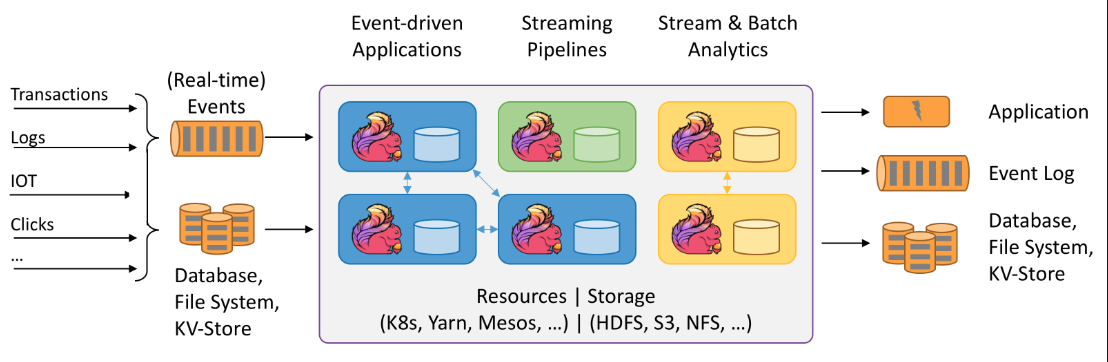
flink apache etl exactly once demo application
So, it is easy to build a real time data pipeline. We can also do the update, delete of mode of ratio on the data table. Here is the example to show how to use Spark Streaming SQL to build the pipeline step by step. Step one, we should create two tables, one source, Kafka table, and another is
19, 2019 · The ability to know how to build an end-to-end machine learning pipeline is a prized asset. As a data scientist (aspiring or established), you should know how these machine learning pipelines work. This is, to put it simply, the amalgamation of two disciplines – data science and software engineering. These two go hand-in-hand for a data ...
Spark's data pipeline concept is mostly inspired by the scikit-learn project. It provides the APIs for machine learning algorithms which make it easier to DataFrame: It is basically a data structure for storing the data in-memory in a highly efficient way. Dataframe in Spark is conceptually equivalent
spark architecture kubernetes data reference k8s
logs. Let’s check the logs of job executions. Here we can see how the pipeline went through steps. To emphasize the separation I have added the echo command in each find the special-lines which I marked in the logs which indicates that job was triggered by another Started by user admin Running in Durability level: MAX_SURVIVABILITY [Pipeline] …
Building Data Pipelines with Microsoft R Server and Azure Data Factory Background Microsoft R Server Azure Data Factory (ADF) Dataset Setup Starting the pipeline Deployment Expectations and further steps Sequence of steps in the R script for training Customizing the pipeline Conclusion.
Spark is a big data solution that has been proven to be easier and faster than Hadoop MapReduce. How to Install PySpark with AWS. The Jupyter team build a Docker image to run Spark efficiently. You will build a pipeline to convert all the precise features and add them to the final dataset.
ML Pipelines provide a uniform set of high-level APIs built on top of DataFrames that help users create and DataFrame: This ML API uses DataFrame from Spark SQL as an ML dataset, which can hold a variety of data types. How it works. A Pipeline is specified as a sequence of stages, and
I am working with Spark on a dataset with ~2000 features and trying to create a basic ML Pipeline, consisting of some Transformers and a Classifier. Let's assume for the sake of simplicity that the Pipeline I am working with consists of a VectorAssembler, StringIndexer and a Classifier,
![]()
azure reference microsoft databricks architecture architectures batch docs icons spark scoring models
Once you understand that apache spark is 'unified' engine for (big) data processing and with each passing days it is offering APIs that can create This can not be offered by a third party tool (IMHO, although vendors shall debate otherwise) and hence in a way Spark helps you to build a
The Spark package is a set of high-level APIs built on DataFrames. A machine learning (ML) pipeline is a complete workflow combining multiple machine learning algorithms together. There can be many steps required to process and learn from data, requiring a sequence of algorithms.
The Spark pipeline object is {Pipeline, PipelineModel} . (This tutorial is part of our Apache Spark Guide. Use the right-hand menu In general a machine learning pipeline describes the process of writing code, releasing it to production, doing data extractions, creating training
28, 2020 · Onboarding new data or building new analytics pipelines in traditional analytics architectures typically requires extensive coordination across business, data engineering, and data science and analytics teams to first negotiate requirements, schema, infrastructure capacity needs, and workload management. For a large number of use cases today however, business …
How to Initiate the Spark Streaming and Kafka Integration. Spark Streaming is an extension to the central application API of Apache Spark. This integration can be understood with a data pipeline that functions in the methodology shown below
